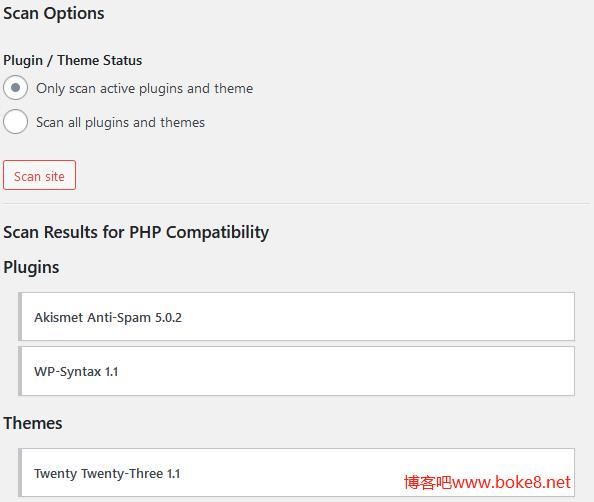
对SEO了解的人应该知道并懂得robots.txt文件的作用及其用法,通过给网站设置适当的robots.txt无论对百度还是谷歌的SEO优化的作用是很明显的。所以为WordPress博客添加robots.txt文件是对博客SEO较为重要的一环,博客吧本篇介绍robots.txt的创建及其用法。
robots.txt的介绍:
robots是机器人的意思,robots.txt文件是给搜索引擎蜘蛛机器人看的纯文本文件,是搜索引擎公认遵循的一个规范文档,它会告诉Google、百度等搜索引擎哪些网页允许抓取、索引并在搜索结果中显示,哪些网页是被禁止收录的。搜索引擎蜘蛛spider(Googlebot/Baiduspider)访问网站页面的时,会先查看网站根目录下是否有robots.txt文件,有则按照文件设置的规则权限对网站页面进行抓取和索引。更具体的作用请网上搜索专门的介绍网站。
robots.txt的写法:
下面是博客吧的robots.txt文件的代码
User-agent:*
Disallow:/wp-
Allow:/wp-content/uploads/
Disallow:/?
Disallow:/feed
Disallow: /trackback
Disallow: /index.php?
Disallow: /*.php$
Disallow: /*.css$
Disallow: /date/
Disallow: /page/
Sitemap: https://www.boke8.net/sitemap.xml
- User-agent: * 表示对所有的搜索引擎都采用下面的规则;
- Disallow: /wp- 不允许Google/百度spider抓取和索引wp-开头的文件及目录,如wp-login.php,wp-admin目录等均被阻止;
- Allow: /wp-content/uploads/ 因为在上一条将wp-content目录屏蔽了,这样Google图片搜索和百度就无法访问放在/wp-content/uploads/目录下的图片, 为了能使Google图片搜索收录图片等附件,将这个目录设置为Allow;
- Disallow: /? 禁止搜索引擎spider索引以?开头的网址,如单独文章页面的动态网址http://farlee.info/?p=1。这一条比较厉害,包括了WordPress博客的大部分动态网址,
- Disallow: /feed 禁止Google,百度搜索引擎索引feed博客页面。博客都有一个订阅整站的feed,每个文章分类,每篇文章也分别有一个feed,feed页面和网站页面内容基本相同,如果feed页面没有被禁止访问,可想而知,这将会产生大量的重复页面。
- Disallow: /trackback作用与/feed一样,不详说
- Disallow: /index.php? 这条规则是为了防止搜索引擎收录abc.com/index.php这种url产生的动态网址
- Disallow: /*.php$ 这条规则是为了禁止搜索引擎访问和收录.php后缀结尾的url,包括abc.com/index.php,有效防止了首页权重被分散。
- Disallow: /*.css$ 禁止搜索引擎访问css文件。
- Disallow: /date/ 禁止搜索引擎访问日期存档页面
- Disallow: /page/ 禁止搜索引擎访问博客文章翻页页面,这里设置后好处是减少了重复页面,坏处是Google和baidu的spider无法检索到老文章,因此这里要和网站地图Sitemap.xml配合使用。
提示:博客吧只说介绍robots.txt,对robots.txt更详细的作用及用法不作讲解。本文大量参照远方博客的相关内容。
提醒:上面的robots.txt文件代码乃博客吧现用的代码,各博主可按自己的情况作增删修改。